本文最后更新于:2023年2月9日 上午
参考博客:知乎文章、知乎文章2、50题搞定data.table
1.修改Rstudio报错信息显示为英文
| Sys.setenv(LANGUAGE = "en")
|
这个设置是临时的,如果需要永久修改,需要修改文件。
2. 清除变量
| rm(object)
rm(list = ls())
gc()
|
3. data.table包
速查表

data.table 包是 data.frame 的高性能版本,不依赖其它包就能胜任各种数据操作,速度超快,让个人电脑都能轻松处理几 G 甚至几十 G 的数据。data.table 的高性能来源于内存管理(引用语法)、并行化和大量精细优化。
但是,与 tidyverse 一次用一个函数做一件事,通过管道依次连接整洁地完成复杂事情 的理念截然不同,data.table 语法高度抽象、简洁、一致:

一句话概括:用 i 选择行,用 j 操作列,根据 by 分组。
3.1 特殊符号
data.table 提供了一些辅助操作的特殊符号:
.(): 代替 list() :=: 按引用方式增加、修改列.N: 行数.SD: 每个分组的数据子集,除了 by 或 keyby 的列.SDcols: 与 .SD 连用,用来选择包含在.SD 中的列.BY: 包含所有 by 分组变量的 list.I: 整数向量 seq_len(nrow(x)),例如 DT[, .I[which.max(somecol)], by=grp] .GRP: 分组索引,1 代表第 1 分组,2 代表第 2 分组,. . ..NGRP: 分组数.EACHI: 用于 by/keyby = .EACHI 表示根据 i 表达式的每一行分组
3.2 数据读写
函数 fread() 和 fwrite() 是data.table 最强大的函数之二。它们最大的优势,仍是读取大数据时速度超快(100 倍),且非常稳健,分隔符、列类型、行数都是自动检测;它们非常通用,可以处理不同的文件格式(但不能直接读取 Excel 文件),还可以接受 URLs 甚至是操作系统指令。
读入数据
| fread("DT.csv")
fread("DT.txt", sep = "\t")
fread("DT.csv", select = c("V1", "V4"))
fread("DT.csv", drop = "V4", nrows = 100)
fread(cmd = "unzip -cq myfile.zip")
fread("myfile.gz")
c("DT.csv", "DT.csv") %>%
lapply(fread) %>%
rbindlist()
|
写出数据
| fwrite(DT, "DT.csv")
fwrite(DT, "DT.csv", append = TRUE)
fwrite(DT, "DT.txt", sep = "\t")
fwrite(setDT(list(0, list(1:5))), "DT2.csv")
fwrite(DT, "myfile.csv.gz", compress = "gzip")
|
3.3 数据连接
data.table 提供了简单的按行合并函数:
rbind(DT1, DT2, ...): 按行堆叠多个data.tablerbindlist(DT_list, idcol): 堆叠多个data.table构成的 list
最常用的六种数据连接:左连接、右连接、内连接、全连接、半连接、反连接,前四种连接又称为修改连接,后两种连接又称为过滤连接。
左连接
外连接至少保留一个数据表中的所有观测,分为左连接、右连接、全连接,其中最常用的是左连接:保留 x 所有行,合并匹配的 y 中的列。
| y[x, on = "v1"]
y[x]
merge(x, y, all.x = TRUE, by = "v1")
|

上面代码提供了左连接的三种不同实现,为了易记性和可读性, 更建议用第三种 merge() 函数。

右连接
保留 y 所有行,合并匹配的 x 中的列:
| merge(x, y, all.y = TRUE, by = "v1")
|
内连接
内连接是保留两个数据表中所共有的观测:只保留 x 中与 y 匹配的行,合并匹配的 y 中的列:
全连接
保留 x 和 y 中的所有行,合并匹配的列:
| merge(x, y, all = TRUE, by = "v1")
|
半连接
根据在 y 中,来筛选 x 中的行:
| x[y$v1, on = "v1", nomatch = 0]
|
反连接
根据不在 y 中,来筛选 x 中的行:
集合运算
| fintersect(x, y)
fsetdiff(x, y)
funion(x, y)
fsetequal(x, y)
|
3.4 数据操作
选择行
用 i 表达式,选择行。
根据索引
根据逻辑表达式
| dt[v2 > 5]
dt[v4 %chin% c("A","C")]
dt[v1==1 & v4=="A"]
|
删除重复行
| unique(dt)
unique(dt, by = c("v1","v4"))
|
删除包含 NA 的行
行切片
| dt[sample(.N, 3)]
dt[sample(.N, .N * 0.5)]
dt[frankv(-v1, ties.method = "dense") < 2]
|
其它
| dt[v4 %like% "^B"]
dt[v2 %between% c(3,5)]
dt[between(v2, 3, 5, incbounds = FALSE)]
dt[v2 %inrange% list(-1:1, 1:3)]
dt[inrange(v2, -1:1, 1:3, incbounds = TRUE)]
|
排序行
| dt[order(v1)]
dt[order(-v1)]
dt[order(v1, -v2)]
|
若按引用对行重排序:

操作列
用 j 表达式操作列。
选择一列或多列
|
dt[[3]]
dt[, 3]
dt[, .(v3)]
dt[, .(v2,v3,v4)]
dt[, v2:v4]
dt[, !c("v2","v3")]
|
反引用列名
tidyverse 提供了丰富的选择列的辅助函数,而 data.table 需要字符串函数、正则表达式构造出列名向量,再通过反引用选择相应的列。
| cols = c("v2", "v3")
dt[, ..cols]
dt[, !..cols]
cols = paste0("v", 1:3)
cols = union("v4", names(dt))
cols = grep("v", names(dt))
cols = grep("^(a)", names(dt))
cols = grep("b$", names(dt))
cols = grep(".2", names(dt))
cols = grep("v1|X", names(dt))
dt[, ..cols]
|
调整列序
| cols = rev(names(DT))
setcolorder(DT, cols)
|
修改列名
修改因子水平
| DT[, setattr(sex, "levels", c("M", "F"))]
|
tidyverse 是用 mutate() 修改列,不修改原数据框,必须赋值结果;data.table 修改列,是用列赋值符号 := (不执行复制),直接对原数据框修改。
修改或增加一列
| dt[, v1 := v1 ^ 2][]
dt[, v2 := log(v1)]
dt[, .(v2 = log(v1), v3 = v2 + 1)]
|

增加多列
| dt[, c("v6","v7") := .(sqrt(v1), "x")]
dt[, ':='(v6 = sqrt(v1),
v7 = "x")]
|
同时修改多列
tidyverse 是借助 across() 或 _all, _if, _at 后缀选择并同时操作多列;而 data.table 选择并操作多列是借助 lapply() 以及特殊符号:
.SD: 每个分组的数据子集,除了 by 或 keyby 的列.SDcols: 与 .SD 连用,用来选择包含在 .SD 中的列,支持索引、列名、连选、反选、正则表达式、条件判断函数
|
DT = readxl::read_xlsx("datas/ExamDatas.xlsx") %>%
as.data.table()
DT[, lapply(.SD, as.character)]
DT[, lapply(.SD, rescale),
.SDcols = is.numeric]
DT = as.data.table(iris)
DT[, .SD * 10, .SDcols = patterns("(Length)|(Width)")]
|

删除列
| dt[, v1 := NULL]
dt[, c("v2","v3") := NULL]
cols = c("v2","v3")
dt[, (cols) := NULL]
|
重新编码
|
dt[v1 < 4, v1 := 0]
dt[, v1 := fifelse(v1 < 0, -v1, v1)]
dt[, v2 := fcase(v2 < 4, "low",
v2 < 7, "middle",
default = "high")]
|
前移/后移运算
| shift(x, n = 1, fill = NA, type = "lag")
shift(x, n = 1, fill = NA, type = "lead")
|
3.5 分组汇总
用 by 表达式指定分组。
data.table 是根据 by 或 keyby 分组,区别是,keyby 会排序结果并创建键,使得更快地访问子集。
未分组数据框相当于整个数据框作为 1 组,数据操作是在整个数据框上进行,汇总是得到 1 个结果。
分组数据框,相当于整个数据框分成了 m 个数据框,数据操作是分别在每个数据框上进行,汇总是得到 m 个结果。
|
DT = readxl::read_xlsx("datas/ExamDatas_NAs.xlsx") %>%
as.data.table()
|
未分组汇总
| DT[, .(math_avg = mean(math, na.rm = TRUE))]
|
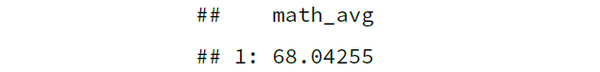
简单的分组汇总
| DT[, .(n = .N,
math_avg = mean(math, na.rm = TRUE),
math_med = median(math)),
by = sex]
|

可以直接在 by 中使用判断条件或表达式,特别是根据整合单位的日期时间汇总:
| date = as.IDate("2021-01-01") + 1:50
DT = data.table(date, a = 1:50)
DT[, mean(a), by = list(mon = month(date))]
|
data.table 提供快速处理日期时间的 IDateTime 类,更多信息可查阅帮助。
对某些列做汇总
| DT[, lapply(.SD, mean), .SDcols = patterns("h"),
by = .(class, sex)]
|
对所有列做汇总
| DT[, name := NULL][,
lapply(.SD, mean, na.rm = TRUE), by = .(class, sex)]
|
对满足条件的列做汇总
| DT[, lapply(.SD, mean, na.rm = TRUE), by = class, .SDcols = is.numeric]
|
分组计数
| DT = na.omit(DT)
DT[, .N, by = .(class, cut(math, c(0, 60, 100)))] %>%
print(topn = 2)
|
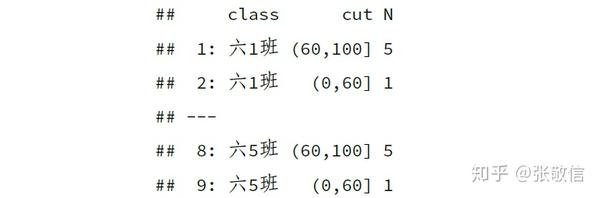
上述分组计数会忽略频数为 0 的分组,若要显示出来可以用:
| DT[, Bin := cut(math, c(0, 60, 100))]
DT[CJ(class = class, Bin = Bin, unique = TRUE), on = c("class","Bin"), .N, by = .EACHI]
|
其中,函数 CJ() 相当于 expand_grid(), 生成所有两两组合(笛卡尔积)。
分组选择行
data.table 也提供了辅助函数:first(), last(), uniqueN(). 比如提取每组的 first/nth 观测:
| DT[, first(.SD), by = class]
DT[, .SD[3], by = class]
DT[, tail(.SD, 2), by = class]
DT[sex == " 男", .SD[math == max(math)], by = class]
|

4. 使用多个条件筛选dataframe
| library(dplyr)
sub_orders = orders%>%filter(is.na(ordr_detl_id)==FALSE, pm_num<0)
|
5. 筛选某列有重复值的所有行
| dup_or = dup_or[duplicated(dup_or$ordr_detl_id),]
|
6. R markdown美化
参考博客:R markdown、Yi hui R markdown cookbook、HTML工具
| knitr::kable(ZZ,format = 'markdown')
|
或使用DT包中的datatable()函数,能实现非常丰富的表格展示,包括筛选、搜索、对列排序、设置滚动条等等,详情见DT
| library(DT)
datatable(ZZ, filter = 'top', options = list(pageLength = 20), caption = 'Table 1: The summary of B2C orders.')
|
设置输出html文件的格式,增加宽度,修改字体,修改字体大小,只需在Rmd文件前加入富文本即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| ---
title: "B2C order exploration"
author: "Mengcheng Guan"
date: "2021/3/2"
output:
html_document:
toc: true
number_section: true
df_print: paged
theme: default
highlight: tango
---
<style type="text/css">
body, td {
font-family: Consolas;
font-size: 14px;
}
code.r{
font-family: Consolas;
font-size: 16px;
}
pre {
font-size: 12px
}
.main-container {
max-width: 1600px; %页面宽度
margin-left: auto;
margin-right: auto;
}
</style>
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
rm(list=ls())
library(data.table)
library(bit64)
```
|
7. 取第一个非空值的值(与oracle nvl函数相同)
使用包statnet.common
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| library(statnet.common)
a <- NULL
print(a)
print(NVL(a,0))
b <- 1
print(b)
print(NVL(b,0))
print(NVL(NULL,1,0))
print(NVL(NULL,0,1))
print(NVL(NULL,NULL,0))
print(NVL(NULL,NULL,NULL))
NVL(a) <- 2
a
NVL(b) <- 2
b
|
8. 代码学习
| gb_orders[, is_initiator := as.numeric(userid==initiator)]
> child[, table(orders>=offered_num)]
FALSE TRUE
27809 7143
set.seed(9999)
control_userids = sample(non_groupbuy_userids, 50000)
cols = colnames(user_stats)
sub_users[is.na(rcvg_prov_name), rcvg_prov_name := 'unknown']
user_stats[, lapply(.SD, mean, na.rm=T), by=group, .SDcols = setdiff(colnames(user_stats), c('user_id', 'group', 'user_type', 'family_type', 'gender', 'reg_province'))]
|
9. 筛选出所有重复的行
|
vec <- c("a", "b", "c","c","c")
vec[duplicated(vec) | duplicated(vec, fromLast=TRUE)]
df <- data.frame(rbind(c("a","a"),c("b","b"),c("c","c"),c("c","c")))
df[duplicated(df) | duplicated(df, fromLast=TRUE), ]
|
10. 统计某一列NA值个数
11. melt and dcast长宽数据转换
例如tc的column有ordr_time, wrong_revenue,wrong_marketing,wrong_gp_amt,现在需要将这个宽表转换为长表,即只包含ordr_time, variable,其中variable就包含了wrong_revenue,wrong_marketing, wrong_gp_amt。
| tc=orders[,.(wrong_revenue=length(which(isEqual_R==0)),
wrong_marketing=length(which(isEqual_M==0)),
wrong_gp_amt=length(which(isEqual_G==0))),by=ordr_time]
long_tc = melt(tc,id='ordr_time')
|
相反,dcast是将长表展开为宽表,trend的column有ordr_time_cut, cat1_id,total_sales,将每个cat1_id都展开为单独的一列。
| trend = orders[gmv > 0,
.(total_sales = log(sum(gmv))),
by = .(ordr_time_cut = cut(ordr_time, breaks = "month"), cat1_id)]
trend_d = dcast(trend,ordr_time_cut~cat1_id,value.var = "total_sales")
|
12. Plot in R
Dygraphs
dygraphs循环画图不出图解决方案
绘制的图形可以参考我用Rmd制作的报告,见文章Rmarkdown示例。
时间序列的图在用很多包都可以绘制,ggplot2是最基本的,另外可以用Dygraphs, Plotly绘制交互式的图表。下面记录下画时序图时遇到的几个问题:
12.1 ggplot2基本函数
首先介绍ggplo2的一些基本参数:
ggplot(data = df, aes(x = col1, y = col2, group = col3, color = as.factor(col4)))
该函数传入绘图所用的dataframe,ggplot使用melt之后的数据比较方便,也就是长数据。当需要绘制有多个series的图时,需要令参数group等于series所在列,color的设置可以给每个series上不同的颜色,当series所在列是字符格式时,需要用as.factor()。
图形类别有geom_line(),geom_point(),geom_bar()等等。
labs设置X, Y轴名称。
scale_x_date如果X轴是时间,则用此函数可以定义显示的格式以及时间间隔。
theme定义坐标轴刻度内容的角度,如垂直文字。
scale_color_manual当存在多个series的时候,默认的颜色不好看,可以通过此函数设置颜色
当需要转换成交互式的图时,能更好的展示和查看数据,使用ggplotly(p)即可
调色板取色参考博客使用ggplot2和RColorBrewer
示例代码如下:
| trend = orders[gmv > 0,
.(total_sales = log(sum(gmv))),
by = .(ordr_time_cut = cut(ordr_time, breaks = "month"), cat1_name)]
trend$ordr_time_cut = as.Date(trend$ordr_time_cut)
library(RColorBrewer)
getPalette = colorRampPalette(brewer.pal(5, "Set1"))
p = ggplot(data = trend,aes(x=ordr_time_cut,y=total_sales,group=cat1_name,color=as.factor(cat1_name)))+
geom_line()+
geom_point()+
labs(x = "Time", y = "Sales(log) by category 1")+
scale_x_date(date_breaks="1 months",date_labels="%b /%m")+
theme(axis.text.x = element_text(angle=45, hjust=1, vjust=1))+
scale_color_manual(name = "Cat1_name", values = getPalette(length(unique(trend$cat1_name))))
ggplotly(p)
|
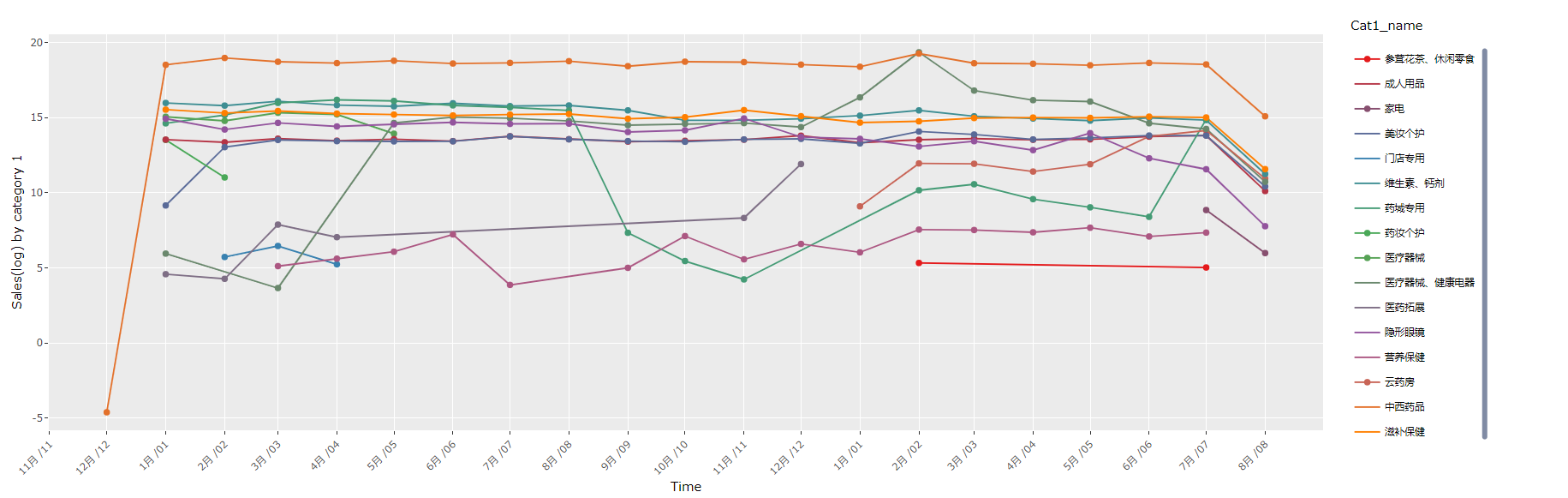
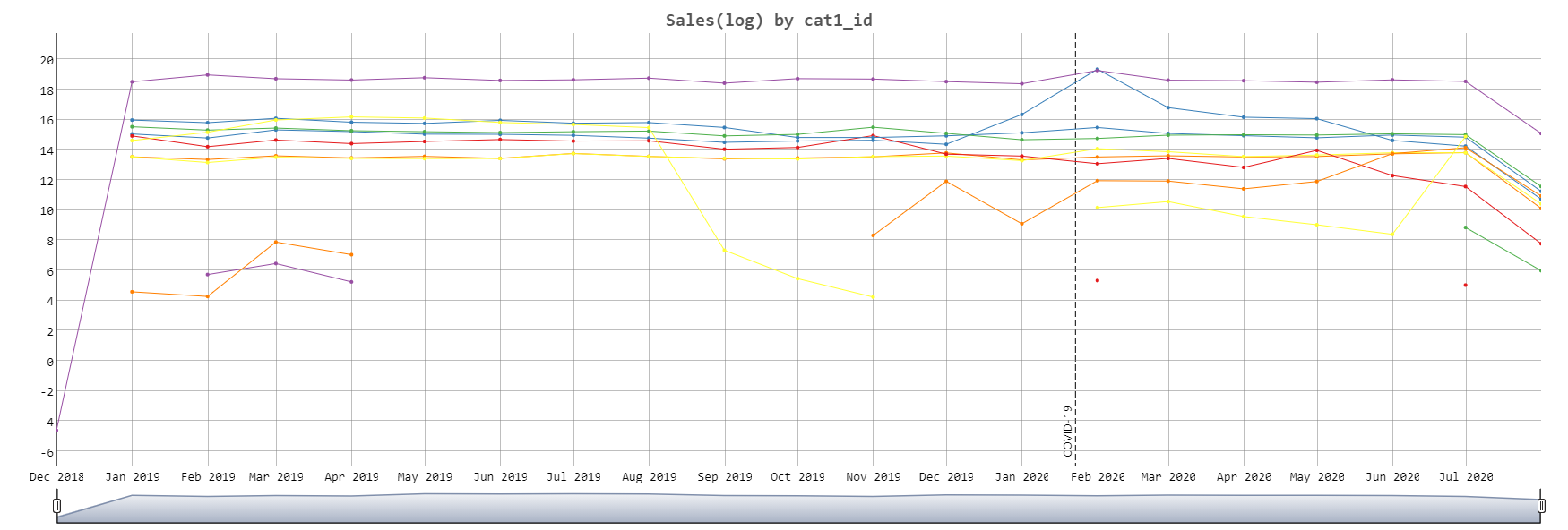
12.2 Dygraph
由于在时间序列数据绘制中,需要插入特定日期的观察线,试了一下用ggplot的geom_vline和geom_segement,效果都不是很理想,最后用Dygraph比较容易实现,但是Dygraph也有很多不足,官网说明不够多,legend的设置比较麻烦,并且在当series很多时,鼠标放在其中一个series的时候所有legend都出来了,目前通过修改css实现了只显示鼠标指向的series的name。
Dygraphs使用宽数据比较方便。
| trend = orders[gmv > 0,
.(total_sales = log(sum(gmv))),
by = .(ordr_time_cut = cut(ordr_time, breaks = "month"), cat1_id)]
trend$ordr_time_cut = as.Date(trend$ordr_time_cut)
trend_d = dcast(trend,ordr_time_cut~cat1_id,value.var = "total_sales")
dygraph(trend_d, main = "Sales(log) by cat1_id")%>%
dyRangeSelector(dateWindow = c("2018-12-01", "2020-08-01"))%>%
dyOptions(colors = RColorBrewer::brewer.pal(6, "Set1"))%>%
dyOptions(drawPoints = TRUE, pointSize = 2) %>%
dyEvent("2020-1-23", "COVID-19", labelLoc = "bottom")%>%
dyLegend(show = "follow")%>%
dyHighlight(highlightSeriesOpts = list(strokeWidth = 3)) %>%
dyCSS(textConnection(" #实现鼠标指向时只显示一个series的name
.dygraph-legend > span { display: none; }
.dygraph-legend > span.highlight { display: inline; }
"))
|
12.3 循环执行ggplotly
当series很多,n>50,则需要分开画
| trend = orders[gmv > 0, .(total_sales = log(sum(gmv))), by = .(ordr_time_cut = cut(ordr_time, breaks = "month"), cat2_name)]
trend$ordr_time_cut = as.Date(trend$ordr_time_cut)
getPalette = colorRampPalette(brewer.pal(5, "Set1"))
split_list = split(unique(trend$cat2_name),1:10)
plotlist = list()
for(i in 1:length(split_list)){
p = ggplot(data = trend[cat2_name %in% split_list[[i]]],aes(x=ordr_time_cut,y=total_sales,group=cat2_name,color=as.factor(cat2_name)))+
geom_line()+
geom_point()+
labs(x = "Time", y = "Sales(log) by cat2_name")+
scale_x_date(date_breaks="1 months",date_labels="%b /%m")+
theme(axis.text.x = element_text(angle=45, hjust=1, vjust=1))+
scale_color_manual(name = "cat2_name", values = getPalette(length(split_list[[i]])))
plotlist[[i]] = print(ggplotly(p))
}
htmltools::tagList(setNames(plotlist, NULL))
|
12.4循环执行Dygraph
当series很多,n>50,则需要分开画
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| trend = orders[gmv > 0, .(total_sales = log(sum(gmv))), by = .(ordr_time_cut = cut(ordr_time, breaks = "month"), cat2_id)]
trend$ordr_time_cut = as.Date(trend$ordr_time_cut)
trend_d = dcast(trend,ordr_time_cut~cat2_id,value.var = "total_sales")
total_num = length(unique(trend$cat2_id))
split_list = split(x=2:total_num,f=1:11)
myfun = function(cut_list){
tmp = c(1,split_list[[cut_list]])
dygraph(trend_d[,..tmp], main = "Sales(log) by cat2_id",group = "My group")%>%
dyRangeSelector(dateWindow = c("2018-12-01", "2020-08-01"))%>%
dyOptions(colors = RColorBrewer::brewer.pal(6, "Set1"))%>%
dyOptions(drawPoints = TRUE, pointSize = 2) %>%
dyEvent("2020-1-23", "COVID-19", labelLoc = "bottom")%>%
dyLegend(show = "follow")%>%
dyHighlight(highlightSeriesOpts = list(strokeWidth = 3)) %>%
dyCSS(textConnection("
.dygraph-legend > span { display: none; }
.dygraph-legend > span.highlight { display: inline; }
"))
}
res = lapply(1:length(split_list), function(i) myfun(i))
htmltools::tagList(res)
|
13 降序
| t3 = t3[order(N,decreasing=T)]
|
14剔除NA数据
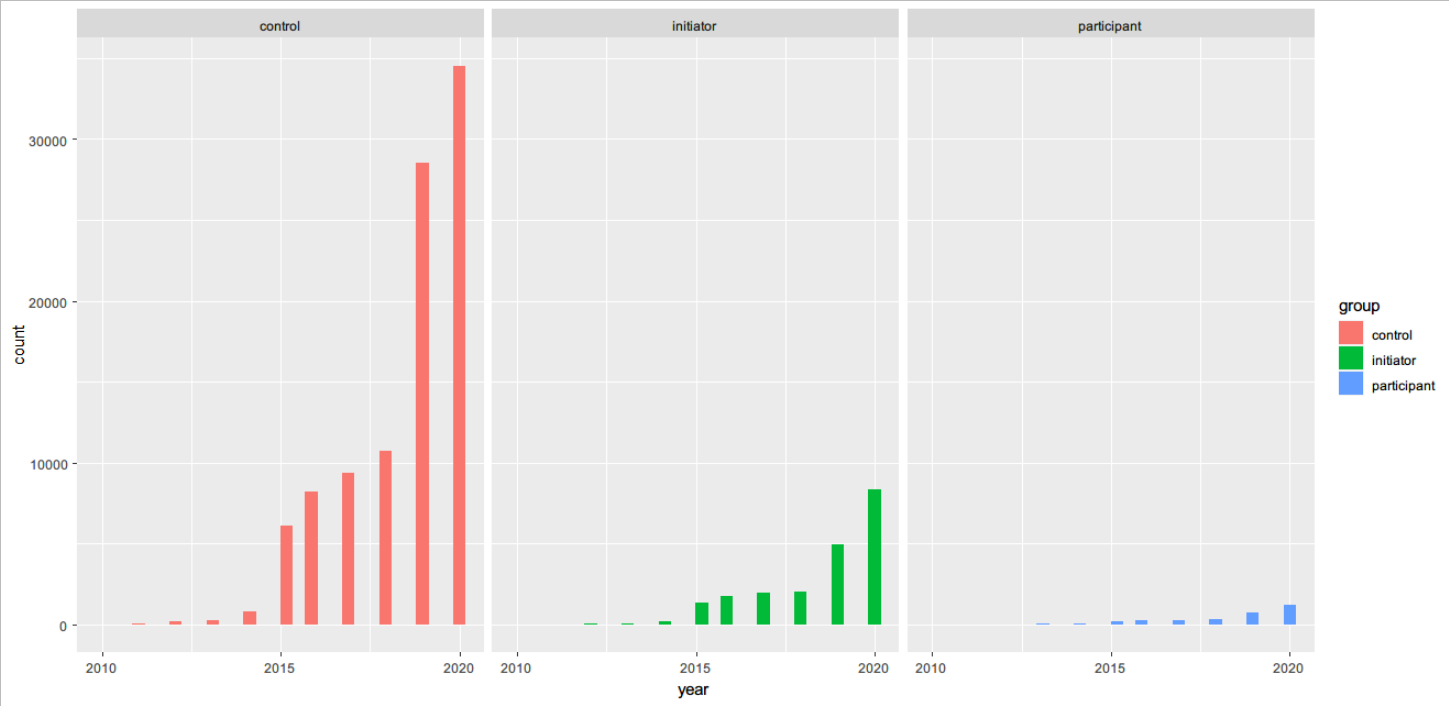
15 分组绘制直方图
| ggplot(sub_users,aes(year,fill=group))+ geom_histogram()+ facet_wrap(~group)
|
16 fillna
|
cols = setdiff(cols, c('user_id', 'price'))
for(col in cols) user_stats[is.na(get(col)), eval(col) := 0]
|
17 字符转换为时间
| gb_orders_clean$ordr_canl_time = as.POSIXct(gb_orders_clean$ordr_canl_time, format="%Y-%m-%d %H:%M:%S", tz='UTC')
|
在进行时间转换的时候,使用POSIXct时间必须要加时区!否则默认为CST时区。
18 计算滚动差值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| library(plyr)
df1 <- aggregate(ab~year+lg+team, FUN=sum, data=baseball)
library(data.table)
DT <- data.table(df1)
DT
Now, look at this concise solution:
DT[, yoy := c(NA, diff(ab)), by = "team,lg"]
DT
|
19 按分组计算每个固定时间间隔内的统计量
参考解答
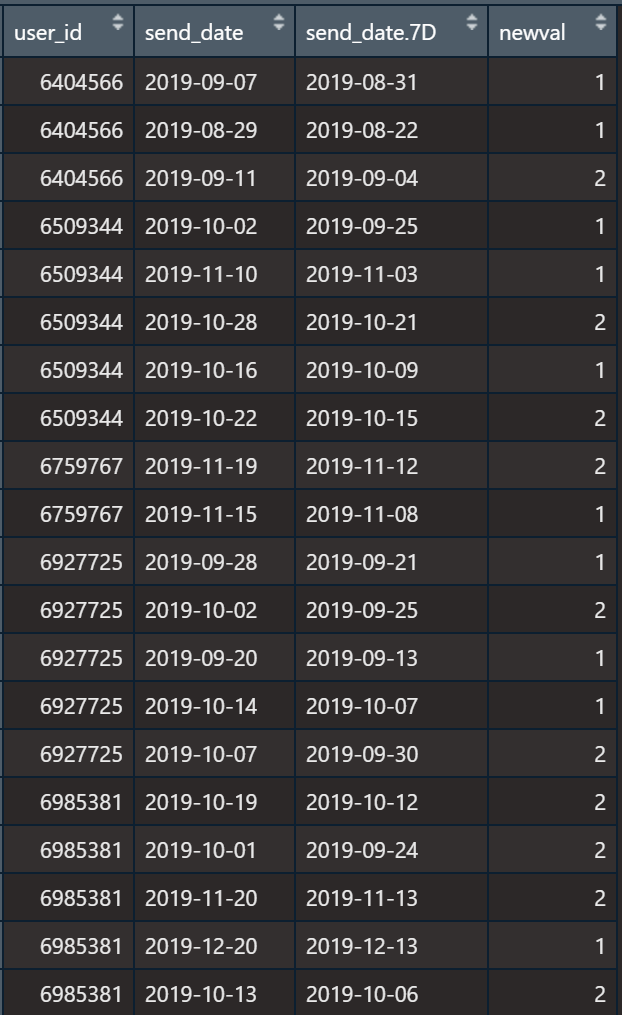
现有如下的数据,需要统计每个user_id,在send_date之前7天至send_date之间有多少条记录,如统计user6404566在其send_date7天内即(2019-8-31,2019-09-07]之间有多少条记录,每行如此。
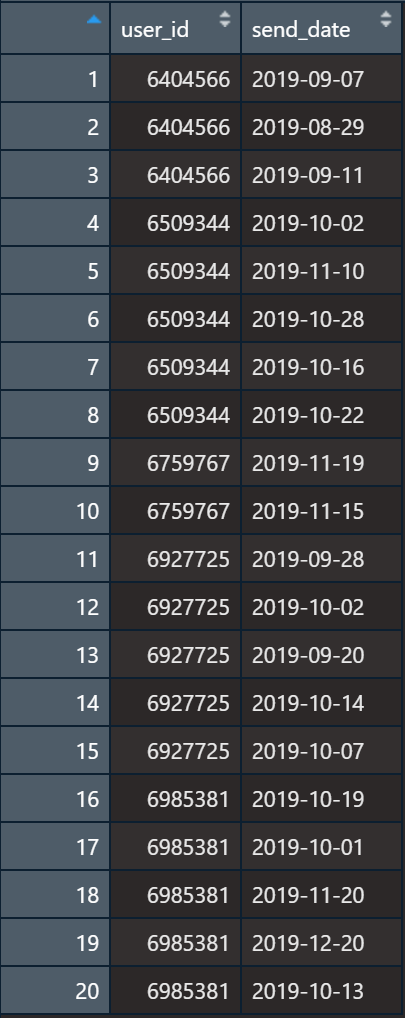
| dat1[,send_date.7D:=send_date-7]
dat1[,newval:= dat1[dat1,on=.(user_id,send_date>send_date.7D,send_date<=send_date),.(N=.N),by=.EACHI]$N]
|
20 统计唯一值个数
参考链接
使用data.table中的nuniqueN函数,有na.rm选项
21 R felm
| felm(IHS(gross_profit)~is_aidrugs*month|pm_id+month|0|pm_id, data=product_panel)
|
按照|看:
第一部分: is_aidrugs*month 是协变量
第二部分: pm_id + month 为两个固定效应
第三部分: 0 为工具变量
第四部分:pm_id 为计算分组稳健标准误的因子
Interactions between a covariate x and a factor f can be projected out with the syntax x:f.
22 PTT warning
Warning in chol.default(mat, pivot = TRUE, tol = tol) :
the matrix is either rank-deficient or indefinite
共线性,不影响结果
23 data.table 密度曲线
| user_panel[,densityplot(avg_gmv)]
|
![[Pasted image 20220329155150.png|500]]
24 转义
要用双引号再加r
25 查看data,table每列类型
26 查找list中特定元素的位置
| > a <- 1:10
[1] 1 2 3 4 5 6 7 8 9 10
> which(a == 5)
[1] 5
|
30 常见偏移窗口函数
巧用R语言中常见的各类偏移窗口函数 - 腾讯云开发者社区-腾讯云 (tencent.com)
如将生成新变量:下一次购买的金额
| panel[, next_price := lead(price), userid]
panel[, re_regret:= ifelse(regret==1 & lead(regret==1),1,0),userid]
|
31 保留每个group中特定序列的行
R - Identify a sequence of row elements by groups in a dataframe - Stack Overflow
如保留每个userid的group中序列为1,-1或1,0的行,使用dplyr库:
| xtt2 = test %>%
group_by(userid) %>%
mutate(new = diff_regret==1 & (lead(diff_regret==0)|
lead(diff_regret==-1)),g=cumsum(new)) %>%
filter(new | lag(new))
|
32 格式化输出回归结果
整理R输出——stargazer - 知乎 (zhihu.com)
使用package stargazer,可以输出text, html, doc
|
PTT = felm(Next_price~regret+
log(popularity)+
day_flag+
weekday_flag+
log(user_experience)+
time_used+
log(user_prior_purchase)|userid+group_id|0|userid, data=panel)
summary(PTT)
stargazer(PTT,type="text",add.lines = list(c('User Fixed Effect','Yes'),
c('Product Fixed Effect','Yes')))
|
33 Rstudio同步至github
RStudio Git GitHub配合使用 - 知乎 (zhihu.com)
34 修改Rstudio安装包安装目录
(24条消息) Rstudio更改工作路径&安装包路径_princess yang的博客-CSDN博客_rstudio改变包的安装位置
35