Python数据分析日常
本文最后更新于:2023年2月20日 下午
总结一下在使用python进行数据分析的过程中碰到的问题及解决方案:smile:。
1 Python连接MYSQL数据库
1 | |
2 写入xlsx文件(多个sheet)
1 | |
3 DataFrame按某列排序
1 | |
4 取出DataFrame某列中非空的行
1 | |
5 Pandas读取xlsx文件的sheetname
1 | |
6 DataFrame中的apply方法
可以自定义函数使用apply方法1
2
3
4
5def get_expire(arr,x,y):
a=arr[x]
b=arr[y]
cur.execute(SQL)
return cur.fetchall()[0][0]
df数据为: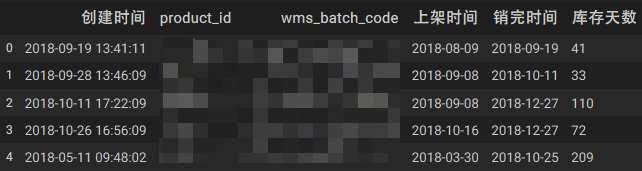
1
df['失效日期']=df.apply(get_expire,axis = 1, args = ('product_id','wms_batch_code')
在get_expire函数中,arr传入的为df,x,y传入分别为'product_id','wms_batch_code'
7 按时间统计数据
首先需要将时间to_datetime,利用方法:
df['cal_date']=pd.to_datetime(df['cal_date'])
然后设置时间列为索引:
df=df.set_index('cal_date')
然后就可以按周、月、季度、年进行统计
df.resample('M')['col1'].sum()
聚合方式还有:
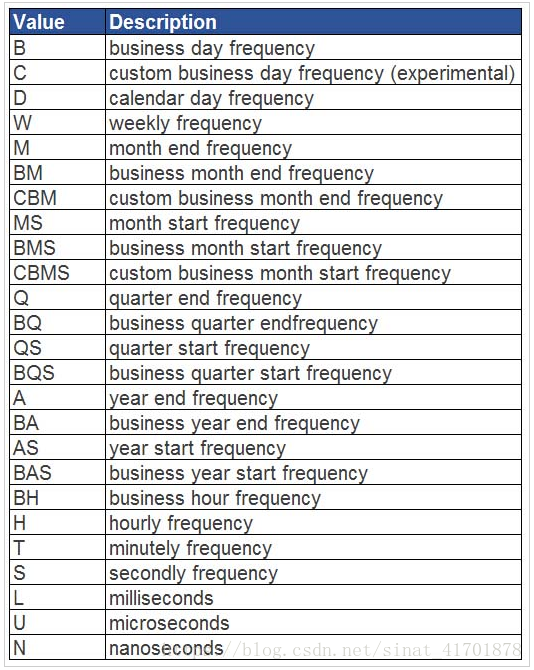
8 获取DataFrame中某列包含特定字符的所有行
1 | |
9 取时间中的天数
batch['库存天数']=(batch['销完时间']-batch['上架时间']).dt.days
10 按特定的值取DataFrame中的行
1 | |
表示取出’出库类型’列中值为’销售订单’,’电商订单’的所有行
11 删除DataFrame中的重复值
1 | |
表示删除batch中’product_id’,’wms_batch_code’均重复的行,保留第一个重复的行,并替换掉原batch
12 合并DataFrame
1 | |
df 与 df1的列相同,将其合并,并忽略各自的index
13 DataFrame的Merge方法
1 | |
how还可取inner,outer,right
14 改变某列的数据类型
1 | |
15 选取以字母G开头的数据
1 | |
16 Group by方法
对DataFrame进行分组,agg方法可实现对多个方法同时使用:
1 | |
agg方法可以实现对同一列实现不同方法{'upric':['mean','var'],也可以对不同列使用不同的方法。
17 Concat合并
将两个DataFrame按照行的维度进行合并
1 | |
按列的维度进行合并
1 | |
18 删除有缺失值的行
1 | |
19 优秀的第三方库
Statsmodels:统计建模和计量经济学
Pandas Profiling:一键生成数据分析报告
20 多层索引处理

1 | |
将第二层的索引合并到第一层,得到

21 重命名列名
1 | |
22 唯一值ID替换
将列中的相同唯一值替换为其他值,可用于脱敏处理,参考
1 | |
24 根据另一个DataFrame更新当前DataFrame的某一列值(两种方法)
分别有两个DataFrame,df1为:

df2为:

df1 中#SEQ编号为207931和207932的行的交付区域为空,我们想要根据df2中对应的交付区域更新df1中的交付区域
1 | |
即可得到最终的df1为:

由于#SEQ作为索引时有重复索引值存在,因此换一种方法
2.
1 | |
25 Dataframe 稀疏矩阵转换
26 One-hot编码转换
pd.get_dummies()
27 读取HDF5文件,其路径不能有中文
28 Dataframe输出是保留开头的0
29 Groupby后计算各行占比
1 | |
30 比较两列是否相同,生成第三列
1 | |
31 vscode python 在Interactive window中运行
在vscode中运行python代码,默认是在终端中运行,如下:
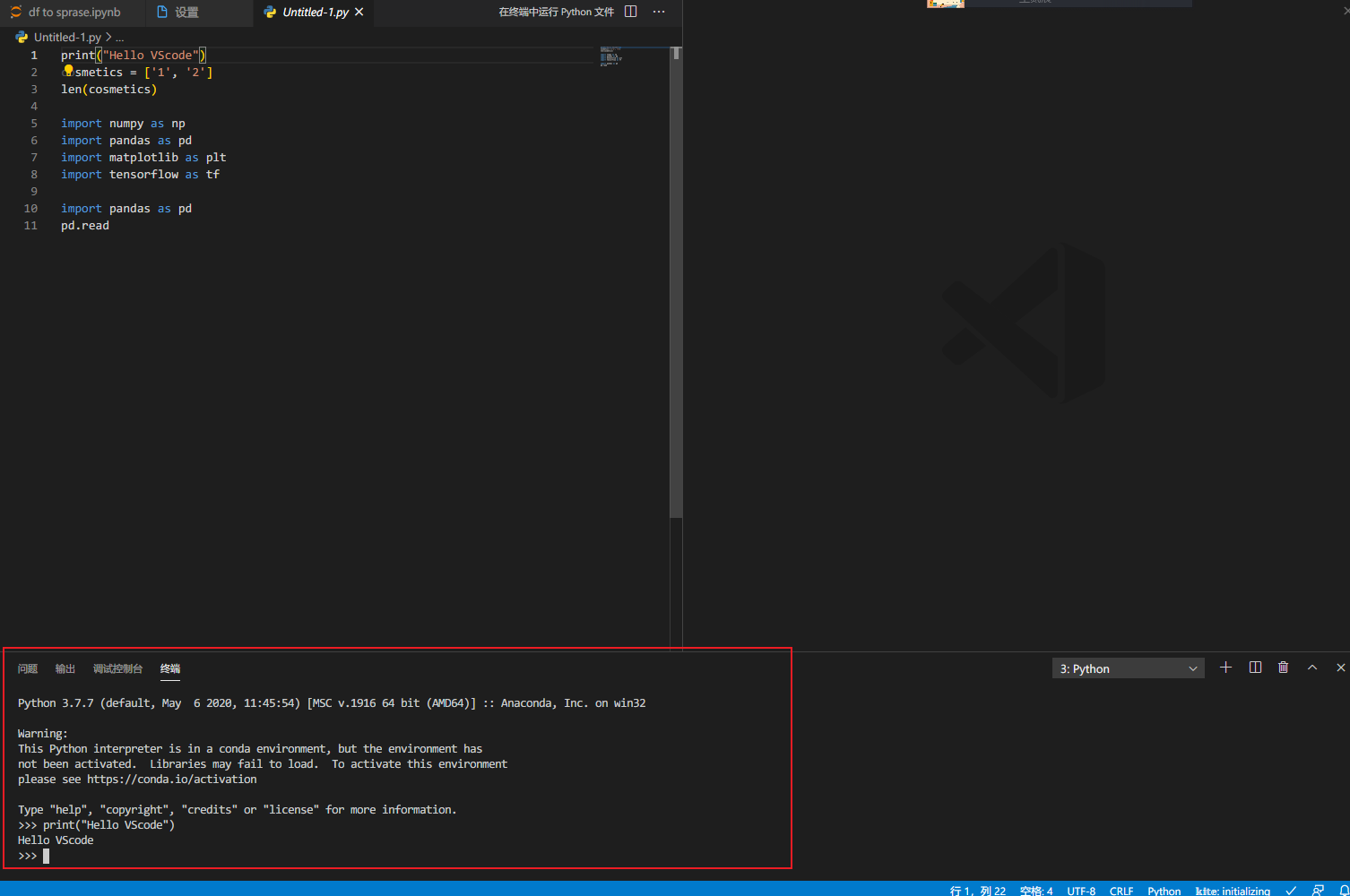
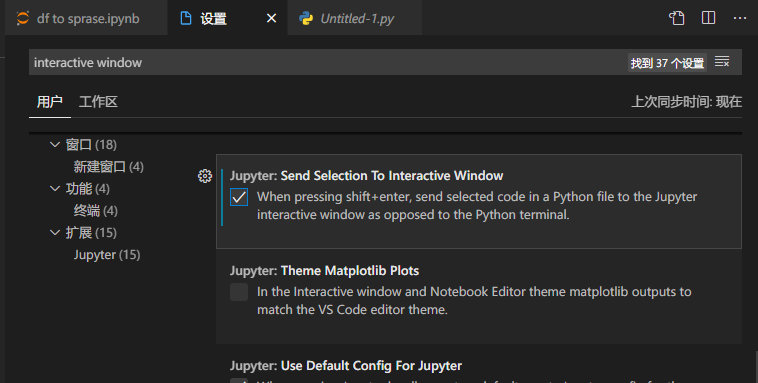
要想在Interactive window中运行需要进入vscode设置,搜索interactive window,勾选即可
33 Vscode中显示dataframe的所有列
1 | |
34 机器学习调参
【机器学习小论文】sklearn随机森林RandomForestRegressor代码及调参_小胡同1991的博客-CSDN博客_randomforestregressor调参
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!